
الگوریتم های Machine Learning برای آسان تر کردن زندگی و بهبود سیستم ها طراحی شده اند، اما می توانند منحرف شوند و با عواقب بدی روبه رو شوند.
هوش مصنوعی و Machine Learning بسیاری از پیشرفت هایی را که امروزه در صنعت فناوری میبینیم، ایجاد می کنند. اما چگونه به ماشین ها توانایی یادگیری داده می شود؟ علاوه بر این، نحوه انجام این کار چگونه منجر به عواقب ناخواسته می شود؟
در این مقاله به صورت کامل مورد نحوه عملکرد الگوریتم های Machine Learning توضیح داده شده است، همراه با چند نمونه از Machine Learning که دچار اشتباه شده است.
الگوریتم های Machine Learning چیست؟
Machine Learning شاخه ای از علوم کامپیوتر است که بر روی دادن توانایی هوش مصنوعی برای یادگیری وظایف تمرکز دارد. این شامل توسعه توانایی ها بدون کدنویسی صریح هوش مصنوعی توسط برنامه نویسان برای انجام این کارها می شود. در عوض، هوش مصنوعی قادر است از داده ها برای آموزش خود استفاده کند.
برنامه نویسان از طریق الگوریتم های Machine Learning به این امر دست می یابند. این الگوریتمها مدل هایی هستند که رفتار یادگیری هوش مصنوعی بر اساس آنها است. الگوریتم ها در ارتباط با مجموعه داده های آموزشی، هوش مصنوعی را قادر به یادگیری می کنند.
یک الگوریتم معمولاً مدلی را ارائه می دهد که هوش مصنوعی می تواند از آن برای حل یک مسئله استفاده کند. به عنوان مثال، یادگیری نحوه تشخیص تصاویر گربه در مقابل سگ. هوش مصنوعی مدل تعیین شده توسط الگوریتم را در مجموعه داده ای که شامل تصاویر گربه ها و سگ ها است، اعمال می کند. با گذشت زمان، هوش مصنوعی یاد میگیرد که چگونه گربه ها را از سگ ها به طور دقیق تر و آسان تر و بدون دخالت انسان تشخیص دهد.
Machine Learning فناوری هایی مانند موتورهای جستجو، دستگاه های خانه هوشمند، خدمات آنلاین و ماشین های مستقل را بهبود می بخشد. این نشان می دهد که چگونه نتفلیکس می داند از کدام فیلم ها بیشتر لذت می برید و چگونه سرویس های پخش موسیقی می توانند لیست های پخش را توصیه کنند.
اما در حالی که Machine Learning می تواند زندگی ما را بسیار آسان تر کند، می تواند عواقب غیرمنتظره ای نیز داشته باشد.
7 موقعیتی که Machine Learning دچاراشتباه شد
1. نتایج نادرست جستجوی تصویر گوگل
جستجوی گوگل پیمایش در وب را بسیار آسان کرده است. الگوریتم موتور هنگام به دست آوردن نتایج، موارد مختلفی مانند کلمات کلیدی و نرخ bounce را در نظر می گیرد. اما الگوریتم همچنین از ترافیک کاربر یاد می گیرد که می تواند کیفیت نتایج جستجو را با مشکل مواجه کند.
این در هیچ کجا بیشتر از نتایج تصویر آشکار نیست. از آنجایی که صفحاتی که ترافیک بالایی دریافت میکنند، احتمالاً تصاویرشان نمایش داده میشود، داستانهایی که تعداد زیادی از کاربران را به خود جذب میکنند، اغلب در اولویت قرار می گیرند.
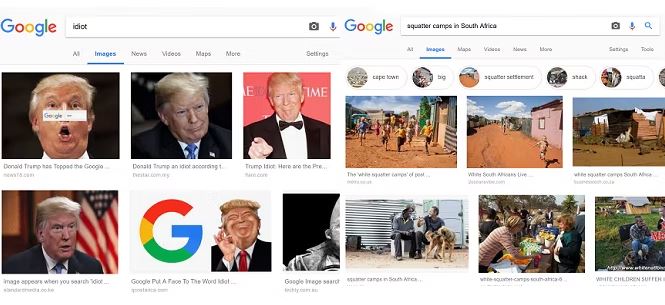
به عنوان مثال، نتایج جستجوی تصویر برای «اردوگاههای غیر رسمی در آفریقای جنوبی» زمانی که مشخص شد که عمدتاً سفید پوستهای آفریقای جنوبی را نشان میدهد، جنجال ایجاد کرد. این در حالی است که آمارها نشان می دهد که اکثریت قریب به اتفاق کسانی که در خانه های غیررسمی مانند کلبه ها زندگی می کنند سیاه پوستان آفریقای جنوبی هستند.
فاکتورهای استفاده شده در الگوریتم گوگل به این معنی است که کاربران اینترنت می توانند نتایج را دستکاری کنند. به عنوان مثال، کمپینی توسط کاربران بر نتایج جستجوی تصویر گوگل تأثیر گذاشت تا جایی که جستجوی عبارت «احمق» تصاویری از دونالد ترامپ، رئیس جمهور آمریکا را نشان می دهد.
2. ربات مایکروسافت به نازی تبدیل شد
به توییتر اعتماد کنید تا یک چت ربات خوش نیت و Machine Learning را خراب کند. این همان چیزی است که در یک روز پس از انتشار چت ربات بد نام مایکروسافت Tay اتفاق افتاد.
Tay الگوهای زبانی یک دختر نوجوان را تقلید کرد و از طریق تعاملاتش با سایر کاربران توییتر یاد گرفت. با این حال، زمانی که شروع به اشتراک گذاری اظهارات نازی ها و توهین های نژادی کرد، او به یکی از بدنام ترین اشتباهات هوش مصنوعی تبدیل شد. به نظر می رسد که ترول ها از یادگیری ماشینی هوش مصنوعی علیه آن استفاده کرده اند و آن را با تعاملات مملو از تعصب پر کرده اند.
چندی بعد، مایکروسافت Tay را برای همیشه آفلاین کرد.
3. مشکلات تشخیص چهره هوش مصنوعی
هوش مصنوعی تشخیص چهره اغلب به دلایل اشتباه، مانند داستان هایی در مورد تشخیص چهره و نگرانی های مربوط به حفظ حریم خصوصی، تیتر خبرها می شود. اما این هوش مصنوعی هنگام تلاش برای تشخیص افراد رنگین پوست باعث نگرانی های زیادی نیز شد.
در سال 2015، کاربران متوجه شدند که Google Photos برخی از سیاه پوستان را به عنوان گوریل دسته بندی می کند. در سال 2018، تحقیقات ACLU نشان داد که نرم افزار شناسایی چهره Rekognition آمازون، 28 عضو کنگره ایالات متحده را به عنوان مظنونان پلیس شناسایی کرده است، با نتایج مثبت کاذب که به طور نامتناسبی بر افراد رنگین پوست تأثیر می گذارد.
یک اتفاق دیگر مربوط به این بود که نرم افزار Face ID اپل به اشتباه دو زن مختلف چینی را به عنوان یک شخص شناسایی کرد. در نتیجه، همکار صاحب آیفون X توانست قفل گوشی را باز کند.
در همین حال، Joy Buolamwini، محقق MIT، به یاد می آورد که اغلب در حین کار روی فناوری تشخیص چهره نیاز به پوشیدن ماسک سفید داشت تا بتواند او را تشخیص دهد. برای حل مسائلی از این دست، Buolamwini و سایر متخصصان فناوری اطلاعات به این موضوع و نیاز به مجموعه داده های جامع تر برای آموزش هوش مصنوعی توجه می کنند.
4. Deepkes مورد استفاده برای حقه
در حالی که مردم مدت هاست از فتوشاپ برای ایجاد تصاویر جعلی استفاده می کنند، Machine Learning این را به سطح جدیدی می برد. نرم افزاری مانند FaceApp به شما امکان می دهد سوژه ها را از یک ویدیو به ویدیوی دیگر تغییر دهید.
اما بسیاری از افراد از این نرم افزار برای مصارف مخرب مختلف، از جمله قرار دادن چهره افراد مشهور در ویدیوهای بزرگسالان یا تولید ویدیوهای دروغین، سوء استفاده می کنند. در همین حال، کاربران اینترنت به بهبود این فناوری کمک کرده اند تا تشخیص ویدیوهای واقعی از جعلی به طور فزاینده ای دشوار شود. در نتیجه، این نوع هوش مصنوعی را از نظر انتشار اخبار جعلی و حقه بازی بسیار قدرتمند می کند.
برای نشان دادن قدرت این فناوری، کارگردان Jordan Peele و مدیر عامل BuzzFeed، Jonah Peretti، ویدئویی ساختند که به نظر می رسد رئیس جمهور سابق ایالات متحده، باراک اوباما، یک PSA در مورد قدرت Deepfake ارائه می دهد.
5. ظهور ربات های توییتر
ربات های توییتر در ابتدا برای خودکارسازی مواردی مانند پاسخ های خدمات مشتری برای برندها ایجاد شدند. اما این فناوری اکنون دلیل اصلی نگرانی است. در واقع، تحقیقات تخمین زده اند که تا 48 میلیون کاربر در توییتر در واقع ربات های هوش مصنوعی هستند.
بسیاری از حسابهای ربات به جای استفاده از الگوریتمها برای دنبال کردن هشتگهای خاص یا پاسخ به سؤالات مشتریان، سعی میکنند از افراد واقعی تقلید کنند. این «افراد» سپس حقهها را تبلیغ می کنند و به انتشار اخبار جعلی کمک می کنند.
موجی از ربات های توییتر حتی تا حدی بر افکار عمومی در مورد برگزیدن و انتخابات ریاست جمهوری 2016 آمریکا تأثیر گذاشت. توییتر خود اعتراف کرد که حدود 50000 ربات ساخت روسیه را که در مورد انتخابات پست می گذاشتند را، کشف کرد.
ربات ها همچنان سرویس را آزار می دهند و اطلاعات نادرست را منتشر می کنند. مشکل به قدری گسترده است که حتی بر ارزش گذاری شرکت نیز تأثیر می گذارد.
6. کارمندان می گویند هوش مصنوعی آمازون تصمیم گرفت مردان را استخدام کند
در اکتبر 2018، رویترز گزارش داد که آمازون مجبور شد ابزار استخدام شغلی را پس از اینکه هوش مصنوعی نرم افزار تصمیم گرفت که نامزدهای مرد ترجیحی هستند را کنار بگذارد.
کارمندانی که می خواستند نامشان فاش نشود، به رویترز آمدند تا در مورد کار خود در این پروژه صحبت کنند. توسعه دهندگان از هوش مصنوعی می خواستند تا بر اساس رزومه آنها بهترین نامزدها را برای یک شغل شناسایی کند. با این حال، افراد درگیر در این پروژه به زودی متوجه شدند که هوش مصنوعی نامزدهای زن را حذف می کند. آنها توضیح دادند که هوش مصنوعی از رزومه های دهه گذشته، که بیشتر آنها از مردان بودند، به عنوان مجموعه داده آموزشی خود استفاده می کرد.
در نتیجه، هوش مصنوعی شروع به فیلتر کردن CV ها بر اساس کلمه کلیدی “زنان” کرد. کلمه کلیدی آنها در رزومه تحت فعالیت هایی مانند “کاپیتان باشگاه شطرنج بانوان” ظاهر شد. در حالی که توسعه دهندگان هوش مصنوعی را تغییر دادند تا از این حذف شدن رزومه های زنان جلوگیری کنند، آمازون در نهایت این پروژه را کنار گذاشت.
7. محتوای نامناسب در YouTube Kids
YouTube Kids ویدیوهای احمقانه و عجیب زیادی دارد که برای سرگرم کردن کودکان طراحی شده است. اما مشکل ویدیوهای اسپم که الگوریتم پلتفرم را دستکاری می کنند نیز دارد.
این ویدیوها بر اساس برچسب های محبوب هستند. از آنجایی که کودکان خردسال بینندگان بسیار دقیقی نیستند، ویدیوهای ناخواسته با استفاده از این کلمات کلیدی میلیون ها بازدید را جذب می کنند. هوش مصنوعی به طور خودکار برخی از این ویدیوها را با استفاده از عناصر پویانمایی استوک، بر اساس برچسب های پرطرفدار تولید می کند. حتی زمانی که فیلم ها توسط انیماتورها ساخته می شوند، عناوین آنها به طور خاص برای پر کردن کلمات کلیدی ایجاد می شود.
این کلمات کلیدی به دستکاری الگوریتم یوتیوب کمک می کنند تا در نهایت به توصیه ها تبدیل شوند. مقدار قابل توجهی از محتوای نامناسب در فیدهای کودکان با استفاده از برنامه YouTube Kids ظاهر شد. این شامل محتوایی می شود که خشونت، ترس و وحشت و محتوای جنسی را به تصویر می کشد.
چرا Machin Learning دچار اشتباه می شود؟
دو دلیل عمده وجود دارد که Machin Learning منجر به عواقب ناخواسته می شود: داده ها و افراد. از نظر داده ها، شعار “آشغال در، ناخواسته” اعمال می شود. اگر داده هایی که به یک هوش مصنوعی داده می شود محدود، مغرضانه یا با کیفیت پایین باشد. در نتیجه یک هوش مصنوعی با دامنه یا سوگیری محدود می شود.
اما حتی اگر برنامه نویسان داده ها را به درستی دریافت کنند، مردم می توانند آچاری را در کار بیاندازند. سازندگان نرم افزار اغلب متوجه نمی شوند که مردم چگونه ممکن است از فناوری به صورت مخرب یا برای اهداف خودخواهانه استفاده کنند. Deepfake از فناوری استفاده شده برای بهبود جلوه های ویژه در سینما به دست آمد.
چیزی که هدفش ارائه سرگرمی های فراگیرتر است، در صورت استثمار، زندگی مردم را نیز نابود می کند.
افرادی هستند که در تلاش برای بهبود پادمان های مربوط به فناوری یادگیری ماشینی برای جلوگیری از استفاده مخرب هستند. اما فن آوری در حال حاضر اینجاست. در همین حال، بسیاری از شرکت ها اراده لازم را برای جلوگیری از سوء استفاده از این پیشرفت ها نشان نمی دهند.
الگوریتم های Machin Learning می توانند به ما کمک کنند
وقتی متوجه میشوید که چقدر Machin Learning و هوش مصنوعی کمتر از انتظارات است، ممکن است کمی غمانگیز به نظر برسد. اما همچنین از بسیاری جهات به ما کمک می کند — نه فقط از نظر راحتی، به طور کلی در بهبود زندگی ما.
اگر کمی در مورد تأثیر مثبت هوش مصنوعی و Machine learning تردید دارید، در مورد راه هایی که هوش مصنوعی با جرایم سایبری و هکرها برای بازگرداندن امنیت مبارزه می کند، کمی مطالعه کنید.





















نظرات کاربران